
I consider myself a very playful person, even at the tender age of 40something. And lately, few toys have brought me more joy than Stable Diffusion. The pure prompt engineering is getting a lot of attention lately, creating images from nothing more than words - and while I understand the fascination, I find it less useful in a creative workflow than "img2img" in Stable Diffusion - the concept of taking one image and using generative AI to turn it into something else. As a creative this means I have much better control over the composition and don't have to start from a blank canvas.
Until recently, img2img was unpredictable and hard to control - but that changed with the release of the research project ControlNet. With that, we have much finer control over the output by analyzing a control image used for input. The control image provides us with edge detection, a normal map, a depth map, or a combination of those for an incredibly precise output.
When I saw the first art created with Stable Diffusion + ControlNet I remembered an idea I tried when I first started experimenting with generative AI in early 2022 - what if I could see the world through the eyes of a child, maybe my own children? See their toys as real life, brought to life by the power of their imagination. We all have that power as children, but over time that power goes away. The technology wasn't quite there in early 2022, but it sure is now. Technology is no substitute for imagination, but it helped me remember how wonderful and rich the world looked when I was a small boy.
Let's back up for a second and show what all this means in practice. By now, we all know what text to image looks like; you put in a written prompt, and the machine spits out an image. Let's see what that looks like with Stable Diffusion and a prompt I've refined.
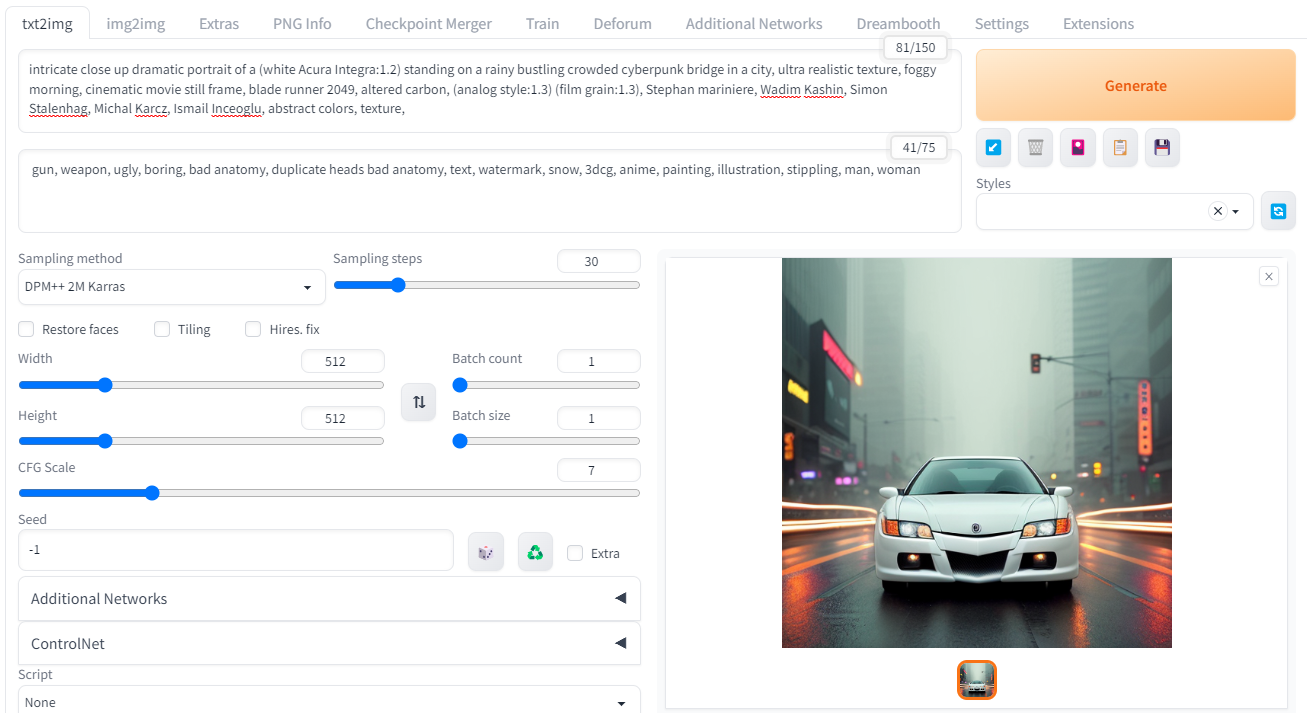
There we go, not a terrible result, but one that needs even work to get it to a specific output. I didn't say what angle I wanted, so the machine decided that for me. Refining this even more is the work of (candidate for 2023 term of the year) prompt engineers. They chose the non-protected term "engineer" because it sounds better than "whisperer" and pays higher salaries.
Img2img is supposed to be the solution to this, giving me a short-cut to creating a specific composition that would be hard to describe in a written prompt. Let's take a photo of my toy Acura Integra, upload that as a reference image for img2img, and see what that does to the output.
Img2img is supposed to be the solution to this, giving me a short-cut to creating a specific composition that would be hard to describe in a written prompt. Let's take a photo of my toy Acura Integra, upload that as a reference image for img2img, and see what that does to the output.
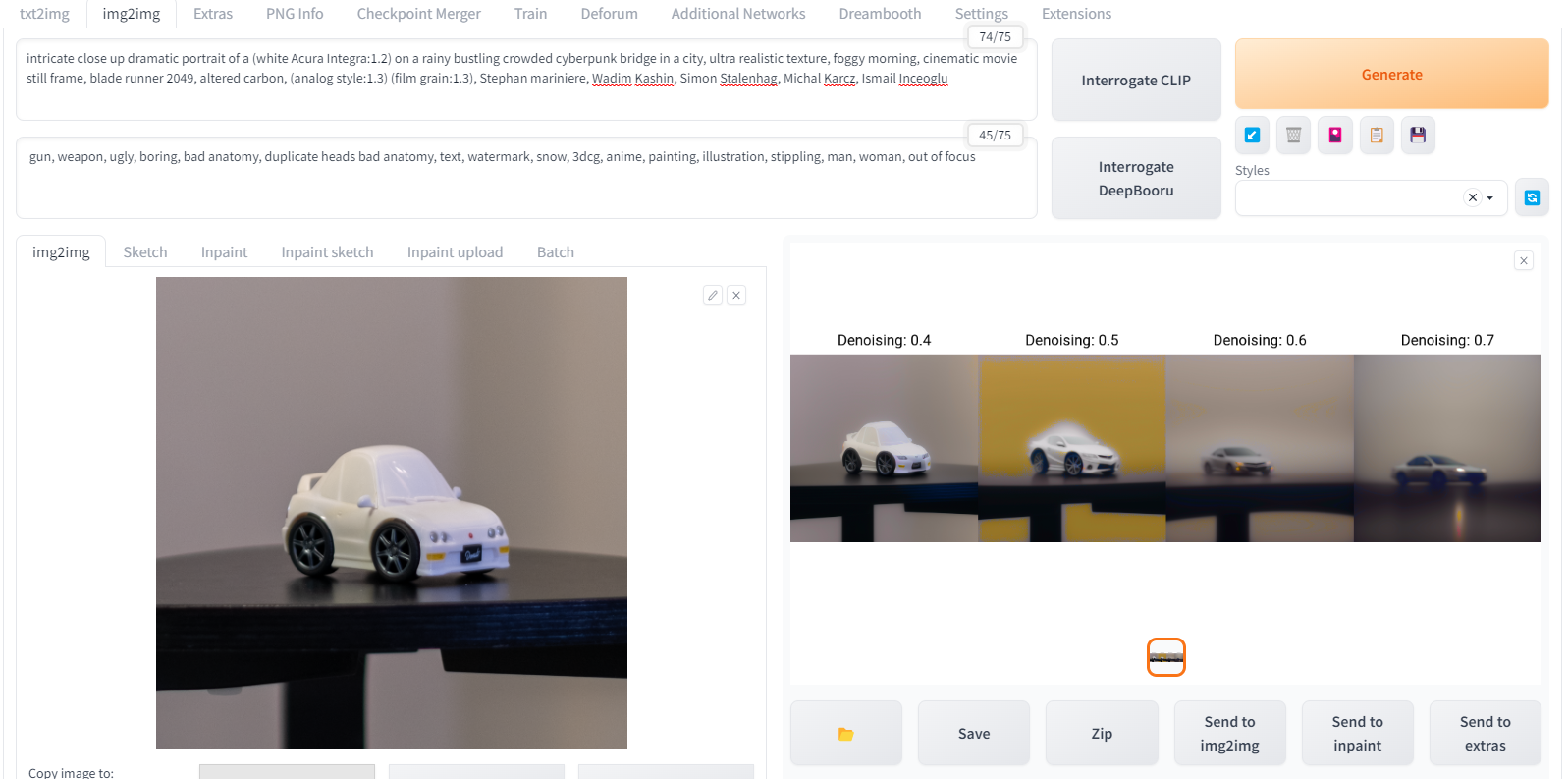
I'm now beginning to have control over my composition. I know I want a front three-quarter shot of the car, so that's what I use as my input. And that's more or less what I get as my output. But as you can see, there are many issues with the output. It takes in the entire reference image, which means the output isn't really doing a great job at following my prompt anymore; all the great details I got in the txt2img output are gone. Also, as I increase the de-noising to let the machine add more generative detail to the output image, the shape of the car is lost, and that shape is an important part of my concept. Last, but not least, because of the very shallow depth-of-field in my reference image, I'm having problems keeping the car in focus, and the entire output gets blurry and out-of-focus.
ControlNet allows me to combine the two, and get not just the best of both worlds, but something BETTER. My input image is used not just as a reference for the diffusion, but also as a control for the generated output. It provides a number of different algorithms for that, so take a look at what three different preprocessors produce from the input image: a depth map on the left, edge detection (Canny) in the center, and a more precise outline detection (HED) on the right:



And now, the moment we've all been waiting for. What happens, when I combine prompt whispering, I mean engineering with img2img + ControlNet.
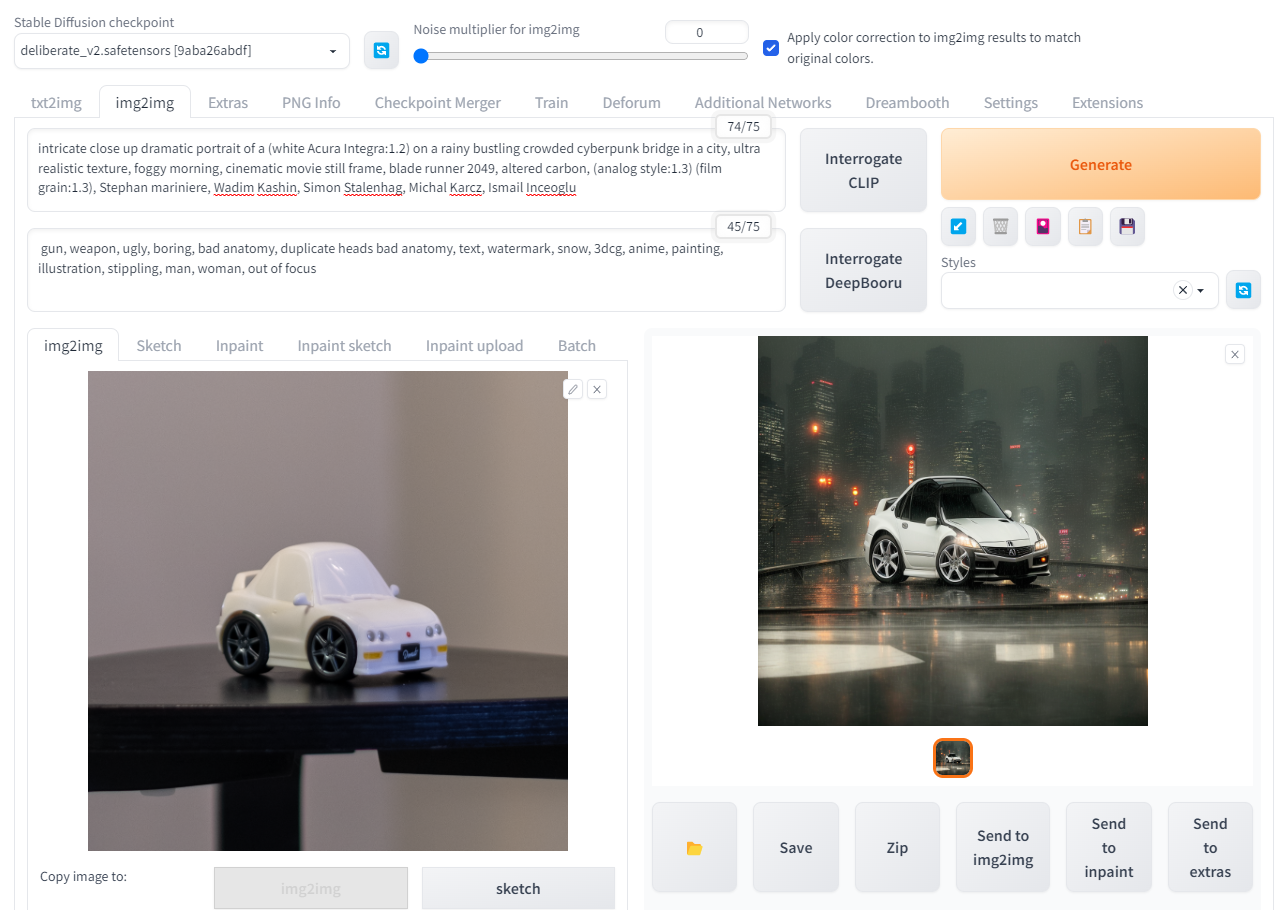
What just happened was magic. My toy car came to life. Stable Diffusion's potential has been fully unlocked with the introduction of ControlNet, and the creative workflow is so satisfying. Below are the toys I've given real life with this approach, spending a few hours tweaking parameters and prompts. The only photoshopping I did was putting an Acura logo on the rear of one of the cars, everything else is straight from the machine. And it wouldn't be a Geppetto Project if I didn't turn Pinnochio into a real boy, would it?















